Training run reset
Update
After the restart, the initial training of test20 (from random games) is not working as expected.
Some network properties are not going where we expected them to go (for example, it’s expected that MSE loss would suddenly drop, but it didn’t. Actually, it jumped up instead, can be followed here). Something is wrong with the training, and we are investigating.
The original plan for that unplanned case was to revert to test10 and do further investigations in background while keeping training test10. However, a person who handles trainings has a personal emergency situation today, so it’s not clear yet if/when the revert will happen.
For now, no training games are generated by contributors, your GPUs are kept cool.
Update2
After more than a day of running the initial training and some training
parameters tweaking, initial network of test20 is taking expected shape (e.g.
MSE loss is dropped).
So, no revert to test10. We’ll start a reinforcement learning stage of test20
soon, so after that short break clients are expected to start generating
training games again.
Update3
test20 training is finally started! First network training from non-random self-play games will be id20058. Networks id20000–20056 were intermediate networks from initial training, and id20057 is the final seed network.
As it was planned, we concluded our test10 run, and now it is time for another
one.
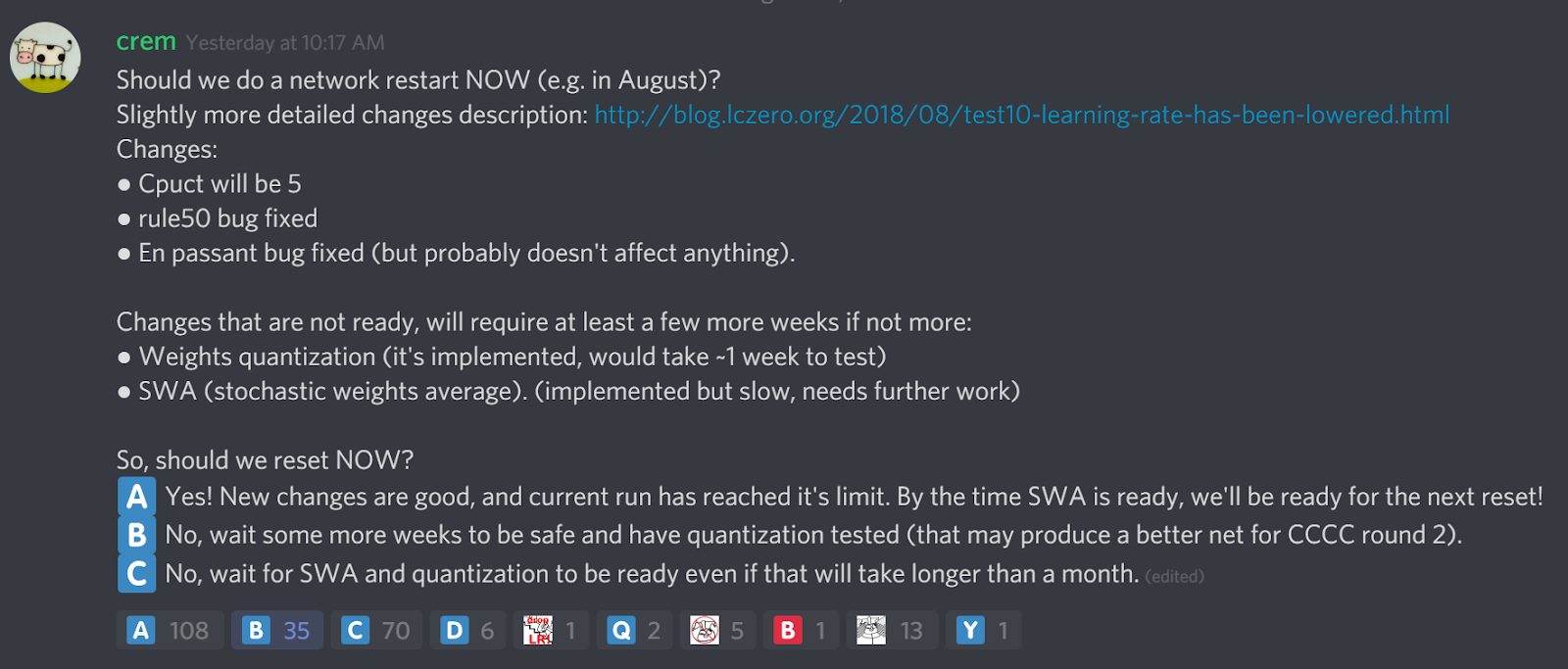
Test10 was undoubtedly a success, but it has reached its limit. The vote on
discord has shown that the community wants the reset as soon as possible, and
that’s what we did. :)
We used to keep network identifiers with test numbers (e.g test5 had network id 5xx), but as we had so many networks for the test10 that it overflown into networks id11xxx, the next test is called test20.
It is expected that at the current game rate it will take 6-7 weeks for test20 to become stronger than latest networks from test10.
Changes
What didn’t change
Before telling what’s new in the next run, let me list what of what we promised, but is not there:
Weights quantization is not enabled.
It is implemented, but we didn’t test it enough to confirm that it doesn’t lead to weaker nets.SWA (Stochastic weights averaging).
Implementation turned out to be too slow, optimizations are needed.Training multiple networks in parallel.
With frequent training that we plan, training pipeline won’t be able to keep up with that.
There are plans to employ several GPUs during training, but that’s not implemented yet.It’s not main2, but rather test20.
It’s running on test server, but at least we updated the server version.
What did change
And now, how test20 will be different from test10:
Cpuct will be equal to 5
That’s the value that Deepmind used in AlphaGo (they did not mention values of Cpuct in AlphaGo Zero and AlphaZero papers).
It is expected that this will make Leela better in tactics, and will add more variance to openings.Rule50 bug fixed.
Leela will be able to use information about number of moves without captures and pawn moves.Cache history bug fixed.
We recently found a bug, that different transposition of the same position could be taken from NN cache, while in reality NN can return different output depending on history. That was fixed.Better resign threshold handling.
We’ll watch at which eval value probability to resign correctly becomes 95% and adjust threshold dynamically.Frequent network generation, ~40 networks per day.
Test10 started with only ~4 networks per day.Larger batch size in training pipeline.
This is closer to what DeepMind did for AlphaZero and should reduce overfitting.Ghost Batch Normalization from start
(I don’t really know what it is). Also closer to what DeepMind did and also prevents overfitting.En passant + threefold repetition bug is fixed.
This was a minor bug which probably won’t have much effect. After pawn move by 2 squares, position was never counted towards three-fold repetition.