A Standard Dataset
When doing machine learning it helps to use a standardized dataset such that methods can be compared in an objective manner. For machine vision, one of the earliest standard datasets is MNIST, a set of handwritten characters that was also used in the (arguably) first deep learning paper.
We should define such a dataset in the world of chess programming as we try to improve training algorithms for our new chess engines based on neural networks. This blogpost introduces such a dataset called the CCRL Dataset (also giving a huge hint as to where it comes from).
Introducing the CCRL Dataset
This dataset was constructed from CCRL 40/40 and 40/4 data combined. It consists of 2'500'000 games, 20% of which is the testset and 80% the trainingset. You can download the dataset in pgn- format (539M) and v3-format (11G).
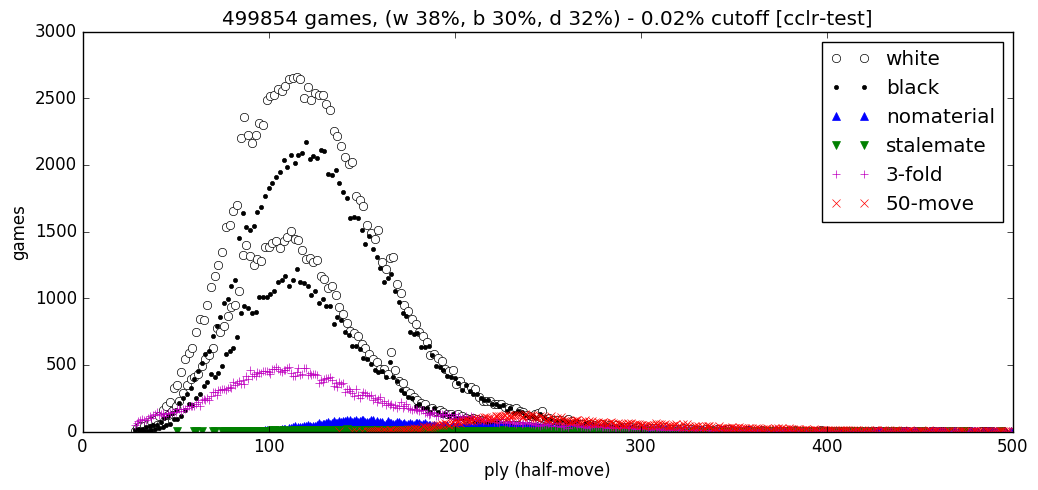
This figure shows a distribution of all the gameover types within the testset of this data. Games with over 500 plies have been excluded from this figure to keep it readable, and as such the game count is slightly smaller than 500'000 with 0.02% ignored. The double bands for black/white wins show wins on checkmates and resignations. 38% was won with white, 30% with black and 32% draw. Finally, the testset has ~86% unique positions (including history planes).
Baseline results
For training a simple baseline network the following yaml scheme was used as input to train.py :
%YAML 1.2 -–name: ‘128x10-base’gpu: 0
dataset: num_chunks: 2500000
train_ratio: 0.80
input_train: ‘/home/fhuizing/Downloads/chess/computer/cclr/v3/train/’
input_test: ‘/home/fhuizing/Downloads/chess/computer/cclr/v3/test/’
training: batch_size: 1024
num_batch_splits: 1
test_steps: 1000
train_avg_report_steps: 500
total_steps: 200000
checkpoint_steps: 10000
shuffle_size: 250000
lr_values: - 0.1
- 0.01
- 0.001
- 0.0001
lr_boundaries: - 80000 - 140000
- 180000
policy_loss_weight: 1.0 value_loss_weight: 0.01 path: ‘/mnt/storage/home/fhuizing/chess/networks’
model: filters: 128
residual_blocks: 10
…
This resulted in an accuracy of 47.0583% , policy loss of 1.591 and mse loss of 0.10882. The network can be downloaded as ccrl- baseline.pb.gz. The tensorboard graphs can be downloaded as leelalogs- base.tgz.
Potential ideas
For inspiration, here’s a list of ideas where using such a dataset may be useful:
- Testing a multigpu training algorithm
- Different neural network architectures
- Different input encoding (e.g. removing history planes)
- Different move encoding on the policy head
- Finishing resign or adjudicated games to get more endgame data with n-man tablebases
And much more…
Final notes
This dataset is very different from our selfplay data runs which improve over time through reinforcement learning. Sliding a training window across the vast number of games produced by clients as new networks are trained. As such one can only test a subset of ideas/parameters using this data. Still, it’s probably safe to say one should never regress in terms of performance on this dataset.
Have fun experimenting and please share your results ( good or bad, as both can be very useful )!