Understanding Training against Q as Knowledge Distillation.
_
Article by Cyanogenoid, member of Leela Chess Zero development team ._
Recently, Oracle investigated training the value head against not the game outcome z, but against the accumulated value q for a position that is obtained after exploring some number of nodes with UCT [[Lessons From AlphaZero: Improving the Training Target.](https://medium.com/oracledevs/lessons-from- alphazero-part-4-improving-the-training-target-6efba2e71628)]. In this post, we describe some of the experiments with Knowledge Distillation (KD) and relate them to training against q.
**
Background**
Knowledge Distillation (KD) [1 ,
2] is a technique where there are two
neural networks at play: a teacher network and a student network. The teacher
network is usually a fixed, fully-trained network, perhaps of bigger size than
the student network. Through KD, the goal is usually to produce a smaller
student network than the teacher – which allows for faster inference – while
still encoding the same “knowledge” within the network; the teacher teaches
its knowledge to the student. When training the student network, instead of
training with the dataset labels as targets (in our case this is the policy
distribution and the value output), the student is trained to match the
outputs of the teacher.
Experiments & Discussion
KD has been tried on the supervised CCRL dataset
[3] with very good
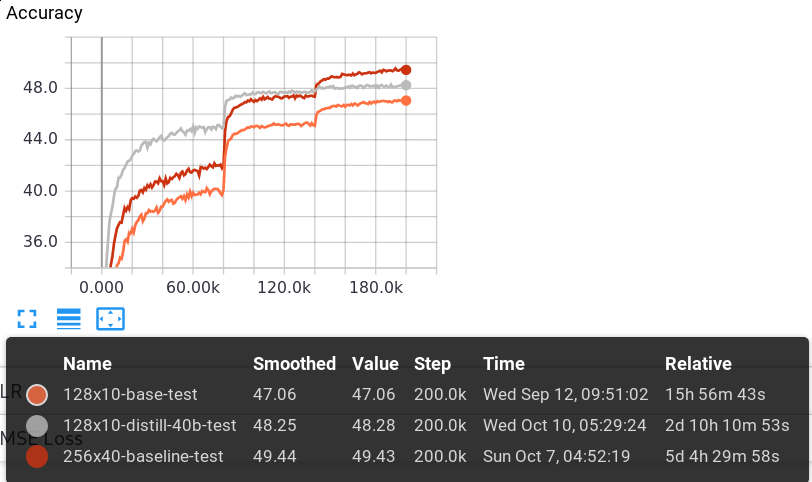
results: A fully-trained 256x40 network has been used as teacher and a 128x10
network as student. Right after the first LR drop, the policy and MSE losses
of the student network were already better than a fully-trained 128x10 network
without the teacher.
The final policy loss was 1.546 compared to the student-only with 1.591 and
the teacher-only with 1.496. This puts the 128x10 student roughly halfway
between performance of the regular 128x10 and the 256x40 network. A similar
thing can be seen with MSE loss, with the 128x10 student being roughly halfway
inbetween the regular 128x10 network and the teacher.
This means that this 128x10 network gains significant amounts of strength
through knowledge distillation while being much smaller and thus faster to run
than the 256x40 network.
One thing to take away from this 40-block to 10-block distillation is that it is important for the teacher to be stronger than the student. While this has been done by making the teacher network bigger than the student network, there is a straightforward way to make any given network stronger within our framework: a network with 800 nodes explored should be stronger than one with only 1 node explored! This is exactly what training against q instead of z would accomplish. Q obtained after 800 nodes can be seen as a weighted ensemble of predictions, and ensembles are known to be very strong and are commonly used as teacher in KD. In other words, the current network is the student and the ensemble of students obtained through UCT is the teacher. By doing this, we remove the requirement of KD of having a separately trained teacher to train the network in the pipeline against, since the teacher is just the student evaluated 800 times.
As Oracle found, it may be a good idea to use the average of q and z as target to avoid q getting into a positive feedback loop to nonsensical values and to limit the horizon effect from a limited number of nodes. Using a linear interpolation of teacher outputs and labels coming from the dataset is a fairly common strategy in KD as well.
One thing that this does not allow when compared to using a separate teacher
is the distillation of the policy head. The difference is that while the value
output can be improved by simulating deeper by using UCT, it is unclear how to
improve policy by simulation through some sort of weighted average through
UCT, other than what we currently do, training against the distribution of
playouts directly.
[4] suggests that even having a student of
the same size as the teacher can improve results, but I haven’t had immediate
success with this. On CCRL, while the student gets decent extremely quickly
(the policy and MSE before the first LR drop was about as good as the policy
and MSE of the teacher just before the **second **LR drop), the final
performance is about the same, perhaps slightly worse than the 128x10 teacher.
However, KD still has some applications for us:
- When bootstrapping a new network, we can use a strong network from a previous run, such as ID 11248 or the latest test20 networks, as teacher at a high LR to get a decent network very quickly. The high LR means that once the teacher is gradually turned off, the student can still unlearn knowledge that is not good fairly quickly.
- There is no requirement on the internal network structure: as long as the output structure is the same, a different network architecture can be used for the student. This allows us to migrate from one network architecture to another (e.g. SE-ResNet)
- Alternatively, we can try to produce tournament networks by using the current network in the pipeline as teacher and training a much smaller student network with slightly worse accuracy from it. This would trade off slightly more inaccurate evaluations for a significant nps increase.
Conclusion
In summary, training against q can be interpreted as a KD process where
knowledge from an ensemble of the student is distilled into the student. With
the experiments, it was confirmed that KD works well on the CCRL dataset with
a fixed teacher network, and argue that this implies great benefits for
training against q and z in some form in the reinforcement learning setting.
Due to the importance of a good value head with high number of nodes (e.g
tournament and analysis settings), it’s believed that incorporating training
against q in addition to z as training target is something we should focus on
in the very near future.
Cyanogenoid’s knowledge distillation code for training nets on CCRL is available HERE.